There is time for dithering in a quantized world of reduced dimensionality!

I’m glad to announce here a new work made in collaboration with Valerio Cambareri (UCL, Belgium) on quantized embeddings of low-complexity vectors, such as the set of sparse (or compressible) signals in a certain basis/dictionary, the set of low-rank matrices or vectors living in (a union of) subspaces.
The title and the abstract are as follows (arxiv link here).
LJ & Valerio Cambareri, “Time for dithering: fast and quantized random embeddings via the restricted isometry property”
Abstract: “Recently, many works have focused on the characterization of non-linear dimensionality reduction methods obtained by quantizing linear embeddings, e.g., to reach fast processing time, efficient data compression procedures, novel geometry-preserving embeddings or to estimate the information/bits stored in this reduced data representation. In this work, we prove that many linear maps known to respect the restricted isometry property (RIP), can induce a quantized random embedding with controllable multiplicative and additive distortions with respect to the pairwise distances of the data points beings considered. In other words, linear matrices having fast matrix-vector multiplication algorithms (e.g., based on partial Fourier ensembles or on the adjacency matrix of unbalanced expanders), can be readily used in the definition of fast quantized embeddings with small distortions. This implication is made possible by applying right after the linear map an additive and random “dither” that stabilizes the impact of a uniform scalar quantization applied afterwards. For different categories of RIP matrices, i.e., for different linear embeddings of a metric space \((\mathcal K \subset \mathbb R^n, \ell_q)\) in \((\mathbb R^m, \ell_p)\) with \(p,q \geq 1\), we derive upper bounds on the additive distortion induced by quantization, showing that this one decays either when the embedding dimension \(m\) increases or when the distance of a pair of embedded vectors in \(\mathcal K\) decreases. Finally, we develop a novel “bi-dithered” quantization scheme, which allows for a reduced distortion that decreases when the embedding dimension grows, independently of the considered pair of vectors.”
In a nutshell, the idea of this article stems from the following observations. There is an ever-growing literature dealing with the design of quantized/non-linear random maps or data hashing techniques for reaching novel dimensionality reduction techniques. More particularly, inside it, some of the works are interested in the accurate control of the number of bits needed to encode the image of the maps, for instance by combining a random linear map with a quantization process approximating the continuous image of the linear map to a finite set of vectors (e.g., using a uniform or a 1-bit quantizer [1,2,3,4]). This quantization is indeed important for instance to reduce and bound the processing time of the quantized signal signatures obtained with this map. In fact, if the quantized map is also an embedding, i.e., if it preserves the pairwise distances of the mapped vectors up to some distortions, we can process the (compact) vector signatures as a proxy to the full processing we would like to perform on the original signals, e.g., for nearest neighbors search or machine learning algorithms.
However, AFAIK, either these random constructions embrace the embedding of general low-complexity vectors sets (possibly continuous) thanks to the quantization of (slow and unstructured) linear random projections (e.g., using a non-linear alteration/quantization of a linear projection reached by a sub-Gaussian random matrix with \(O(mn)\) encoding complexity [1,2,3,4]), or they rely on fast non-linear maps (e.g., exploiting circulant random matrices) which are unfortunately restricted (up to now) to the embedding of finite vector sets [5,6,7].
This is rather frustrating when we know that the compressive sensing (CS) literature now offers us a large class of linear embeddings of low-complexity vector sets, i.e., including constructions with fast (possibly with log-linear complexity) projections of vectors. We can think for instance to the projections induced by partial Fourier/Hadamard ensembles [9], random convolutions [10] or the spread-spectrum sensing [11].
Adopting a general formulation federating several definitions available in different works, this embedding capability is mathematically characterized by the celebrated restricted isometry property (or RIP), i.e., a matrix \(\boldsymbol \Phi \in \mathbb R^{m \times n}\) respects the \((\ell_p, \ell_2)\)-RIP\((\mathcal K - \mathcal K, \epsilon)\) with (multiplicative) distortion \(\epsilon > 0\), if for all \(\boldsymbol x, \boldsymbol x’ \in \mathcal K\) and some \(p \in \{1,2\}\),
\[(1-\epsilon) \|\boldsymbol x - \boldsymbol x’\|^p \leq \tfrac{1}{m} \|\boldsymbol \Phi(\boldsymbol x - \boldsymbol x’)\|_p^p \leq (1+\epsilon) \|\boldsymbol x - \boldsymbol x’\|^p.\]
Given such a matrix \(\boldsymbol \Phi\) and a uniform quantization \(\mathcal Q(\lambda) = \delta (\lfloor \tfrac{\lambda}{\delta}\rfloor + \tfrac{1}{2})\) (with resolution \(\delta > 0\)) applied componentwise onto vectors, we can define the quantized map \(A’(\boldsymbol x) := \mathcal Q(\boldsymbol\Phi\boldsymbol x) \in \delta (\mathbb Z + \tfrac{1}{2})^m\) and easily observe (since \(|\mathcal Q(\lambda) - \lambda| \leq \delta/2\)) that
\[(1-\epsilon)^{1/p} \|\boldsymbol x - \boldsymbol x’\| - \delta \leq \tfrac{1}{\sqrt[p] m} \|A’(\boldsymbol x) - A’(\boldsymbol x’)\|_p \leq (1+\epsilon)^{1/p} \|\boldsymbol x - \boldsymbol x’\| + \delta.\]
Strikingly, we observe now that, compared to the RIP that only displays a multiplicative distortion \(\epsilon\), this last relation contains now an additive – and constant! – distortion \(\delta\), which is the direct expression of the quantization process.
However, our work actually shows that it is nevertheless possible to design quantized embeddings where this new additive distortion can be controlled (and reduced) with either the dimension \(m\) of the embedding domain or with the distance \(\|\boldsymbol x - \boldsymbol x’\|\) of the considered points.
The key is to combine a linear embeddings \(\boldsymbol \Phi\) (i.e., satisfying the \((\ell_p, \ell_2)\)-RIP) with a dithered and uniform quantization process [8], i.e., we insert \(m\) iid uniform random variables on each component of the linear map before quantization. Notice that once randomly generated, as for \(\boldsymbol \Phi\), these dithers must of course be stored. However, such a storage is small (or at most comparable) to the the storage of a RIP matrix, i.e., we must anyway record \(O(mn)\) entries for unstructured matrices and \(O(m)\) values for the lightest structured constructions [9,11,15]. Noticeably, several works already included this dithering procedure as a way to ease the statistical analysis of the resulting map (see, e.g., the constructions defined for universal embeddings [12], the random Fourier features [13] or for locality preserving hashing [4,14]).
Roughly speaking (see the paper for the correct statements), among other things, we show that if a matrix \(\boldsymbol \Phi \in \mathbb R^{m \times n}\) respects the \((\ell_p, \ell_2)\)-RIP\((\mathcal K - \mathcal K, \epsilon)\), then, provided \(m\) is larger than the \(\epsilon’\)-Kolmogorov entropy of \(\mathcal K\) with \(\epsilon’ = \epsilon’(\epsilon)\) being some power of \(\epsilon\) (i.e., for the set of \(k\)-sparse vectors in \(\mathbb R^n\), this would mean that \(m= O\big({\epsilon}^{-2} k \log(n/\delta\epsilon^2 k)\big)\)), the map \(A: \mathbb R^n \to \mathcal E := \delta (\mathbb Z + 1/2)^m\) defined by
\[A(\boldsymbol x) := \mathcal Q(\boldsymbol \Phi \boldsymbol x + \boldsymbol \xi), \quad \mathcal Q(\lambda) = \delta (\lfloor \tfrac{\lambda}{\delta}\rfloor + \tfrac{1}{2}),\ \xi_i \sim_{\rm iid} \mathcal U([0,\delta])\]
is such that, with high probability and given a suitable concept of (pre)metric \(d_{\mathcal E}\) in \(\mathcal E\),
\[d_{\mathcal E}(A(\boldsymbol x), A(\boldsymbol x’)) \approx \|\boldsymbol x - \boldsymbol x’\|^p,\quad \forall \boldsymbol x, \boldsymbol x’ \in \mathcal K,\]
where the approximation symbol hides an additive and a multiplicative errors (or distortions).
More precisely, we have with high probability a quantized form of the RIP, or \((d_{\mathcal E}, \ell_2)\)-QRIP\((\mathcal K, \epsilon, \rho)\), that reads
\[(1-\epsilon) \|\boldsymbol x - \boldsymbol x’\|^p - \rho \leq d_{\mathcal E}(A(\boldsymbol x), A(\boldsymbol x’)) \leq (1+\epsilon) \|\boldsymbol x - \boldsymbol x’\|^p + \rho,\]
for all \(\boldsymbol x, \boldsymbol x’ \in \mathcal K\) and some distortions \(\epsilon\) and \(\rho = \rho(\epsilon, \|\boldsymbol x - \boldsymbol x’\|)\).
Interestingly enough, this last additive distortion \(\rho\) – a pure effect of the quantization in the definition of \(A\) since the linear RIP is not subject to it – truly depends on the way distances are measured both in \(\mathbb R^m\) (for the range of \(\boldsymbol \Phi\)) and in \(\mathcal E\).
For instance, if one decides to measure the distances with the \(\ell_1\)-norm (\(p = 1\)) in these both domains, hence asking \(\boldsymbol \Phi\) to respect a \((\ell_1, \ell_2)\)-RIP, we have
\[\rho\ \lesssim\ \delta \epsilon,\]
as explained in Prop. 1 of our work.
If we rather focus on using \((\ell_2, \ell_2)\)-RIP matrices for defining the quantized map \(A\) (hence allowing for fast and structured constructions) and on measuring the distances with squared \(\ell_2\)-norm in both \(\mathbb R^m\) and \(\mathcal E\), then
\[\rho(\epsilon, s)\ \lesssim\ \delta s + \delta^2 \epsilon,\]
where \(s\) stands for the dependence in the distance. This is expressed in the Prop. 2 of our paper and it shows that for this particular choice of distances, the additive distortion is controllable and small compared to large values of \(s^2 = \|\boldsymbol x - \boldsymbol x’\|^2\), but it only tends to zero if both this distance and the resolution \(\delta\) do so.
Bi-dithered quantized map: Desiring to preserve the inheritance of the \((\ell_2, \ell_2)\)-RIP matrix constructions in the construction of an efficient quantized embedding, i.e., with a smaller distortion \(\rho\) than in the last scheme above, our paper also introduce a novel bi-dithered quantized map.
The principle is really simple. For each row of a RIP matrix, two dithers and thus two measurements are generated (hence doubling the total number \(m\) of measurements). Mathematically, we now define the map \(A: \mathbb R^n \to \mathcal E := \delta (\mathbb Z + \tfrac{1}{2})^{m \times 2}\) with
\[\bar A(\boldsymbol x) := \mathcal Q(\boldsymbol \Phi \boldsymbol x \boldsymbol 1_2^T + \boldsymbol \Xi),\ \boldsymbol \Xi \in \mathbb R^{m \times 2},\ \Xi_{ij} \sim_{\rm iid} \mathcal U([0,\delta]),\]
writing \(\boldsymbol 1_2^T = (1\ 1)\). Then, one can show, and this is Prop. 3 in our paper, that if \(\mathbb R^m\) is endowed with the \(\ell_2\) norm and \(\mathcal E\) with the premetric \(\|\cdot\|_{1,\circ}\) such that
\[\textstyle \| \boldsymbol B \|_{1,\circ} := \sum_i \prod_j |B_{ij}|,\quad \boldsymbol B \in \mathbb R^{m \times 2},\]
then, provided \(m\) is again larger than the \(\epsilon’\)-Kolmogorov entropy of \(\mathcal K\), the map \(\bar A\) does also determine with high probability a quantized embedding of \(\mathcal K\) in \(\mathcal E\) with reduced additive distortion bounded as
\[\rho(\epsilon, s)\ \lesssim\ \delta^2 \epsilon,\]
which is much smaller than what is reached in the case of a single dither.
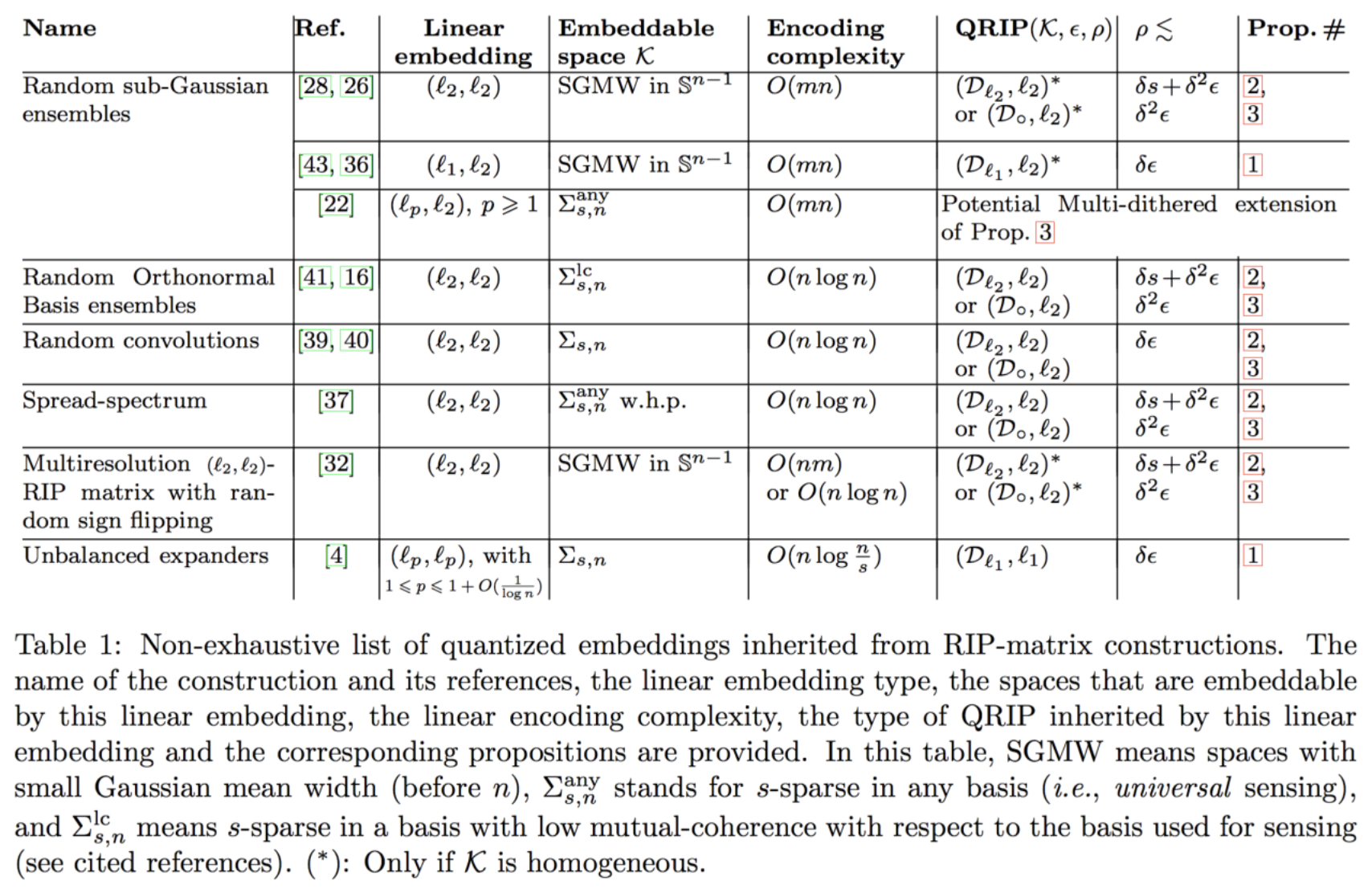
All these results are actually summarized in the following table extracted from the paper (the caption is better understood by reading the paper):
Remark 1 (connection with the “fast JL maps from RIP”-approach): The gist of our work is after all quite similar, in another context, to the standpoint adopted in this paper by Krahmer and Ward for the development of fast Johnson-Lindenstrauss embeddings using the large class of RIP matrix constructions (when combined with a random pre-modulating \(\pm 1\) diagonal matrix) [17].
Remark 2 (on the proofs): The proofs developed in our work are not really technical and are all based on the same structure: the (variant of the) RIP allows us to focus on the embedding of the image of a low-complexity vector set (obtained through the corresponding linear map \(\boldsymbol \Phi\)) into a quantized domain thanks to a randomly dithered-quantization. This is made possible by softening the discontinuous distances evaluated in the quantized domain according to a mathematic machinery inspired by [3] in the case of 1-bit quantization and extended in [16] for dithered uniform scalar quantization (as above). Actually, this softening allows us to extend the concentration of quantized random maps on a finite covering of the low-complexity vector set \(\mathcal K\) to this whole set by a continuity argument.
Remark 3 (on RIP-1 matrices): We do not mention in this post another variant of the RIP above, i.e., embedding \((\mathbb R^n, \ell_1)\) in \((\mathbb R^m, \ell_1)\), that allows us also to inherit of the “RIP-1” matrices developed in [15] (associated to the adjacency matrix of expanders graphs) with distortion \(\rho \lesssim \delta /epsilon\).
Remark 4 (on 1-bit quantized embeddings): If the set \(\mathcal K\) is bounded (e.g., as for the set of bounded sparse vectors), a careful selection of the quantization resolution \(\delta > 0\) actually turns the map \(A\) into a 1-bit embedding! Indeed, each of its components can basically take only two values if \(\delta\) reaches the diameter of \(\mathcal K\).
Open problems:
- Even if Remark 4 above shows us that 1-bit quantized embeddings are reachable with a dithered quantization of RIP-based linear embeddings, it is still an open and challenging problem to understand if fast embeddings can be designed with (undithered) sign operator [5,6,7].
- A generalization of the bi-dithered quantized map above to a multi-dithered version (with of course a careful study of the corresponding increase of the measurement number) could potentially lead us to more advanced and distorted mappings, e.g., where distances are distorted by a polynomial of degree set by the number of dithers attributed to each row of \(\boldsymbol \Phi\).
References:
- [1] P. T. Boufounos and R. G. Baraniuk. 1-bit compressive sensing. In Information Sciences and Systems, 2008. CISS 2008. 42nd Annual Conference on, pages 16–21. IEEE, 2008.
- [2] L. Jacques, J. N. Laska, P. T. Boufounos, and R. G. Baraniuk. Robust 1-bit compressive sensing via binary stable embeddings of sparse vectors. Information Theory, IEEE Transactions on, 59(4):2082–2102, 2013.
- [3] Y. Plan and R. Vershynin. Dimension reduction by random hyperplane tessellations. Dis- crete & Computational Geometry, 51(2):438–461, 2014.
- [4] M. Datar, N. Immorlica, P. Indyk, and V. S. Mirrokni. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on Computational geometry, pages 253–262. ACM, 2004.
- [5] S. Oymak. Near-Optimal Sample Complexity Bounds for Circulant Binary Embedding. arXiv preprint arXiv:1603.03178, 2016.
- [6] F. X. Yu, A. Bhaskara, S. Kumar, Y. Gong, and S.-F. Chang. On Binary Embedding using Circulant Matrices. arXiv preprint arXiv:1511.06480, 2015.
- [7] F. X. Yu, S. Kumar, Y. Gong, and S.-F. Chang. Circulant binary embedding. arXiv preprint arXiv:1405.3162, 2014.
- [8] R. M. Gray and D. L. Neuhoff. Quantization. Information Theory, IEEE Transactions on, 44(6):2325–2383, 1998.
- [9] H. Rauhut, J. Romberg, and J. A. Tropp. Restricted isometries for partial random circulant matrices. Applied and Computational Harmonic Analysis, 32(2):242–254, 2012.
- [10] J. Romberg. Compressive sensing by random convolution. SIAM Journal on Imaging Sciences, 2(4):1098–1128, 2009.
- [11] G. Puy, P. Vandergheynst, R. Gribonval, and Y. Wiaux. Universal and efficient compressed sensing by spread spectrum and application to realistic Fourier imaging techniques. EURASIP Journal on Advances in Signal Processing, 2012(1):1–13, 2012.
- [12] P. T. Boufounos, S. Rane, and H. Mansour. Representation and Coding of Signal Geometry. arXiv preprint arXiv:1512.07636, 2015.
- [13] A. Rahimi and B. Recht. Random features for large-scale kernel machines. In Advances in neural information processing systems, pages 1177–1184, 2007.
- [14] A. Andoni and P.Indyk. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. In Foundations of Computer Science, 2006. FOCS'06. 47th Annual IEEE Symposium on, pages 459–468. IEEE, 2006.
- [15] R. Berinde, A. C. Gilbert, P. Indyk, H. Karloff, and M. J. Strauss. Combining geometry and combinatorics: A unified approach to sparse signal recovery. In Communication, Control, and Computing, 2008 46th Annual Allerton Conference on, pages 798–805. IEEE, 2008.
- [16] L. Jacques. Small width, low distortions: quasi-isometric embeddings with quantized sub- Gaussian random projections. arXiv preprint arXiv:1504.06170, 2015.
- [17] F. Krahmer, R. Ward, “New and improved Johnson-Lindenstrauss embeddings via the restricted isometry property”. SIAM Journal on Mathematical Analysis, 43(3), 1269-1281, 2011.
Image credit: Dithering algorithms to binarize images, the random dithering case, source Wikipedia.